An update on bpfilter
This post will detail the current state of bpfilter and how it approaches features and constraints for packet filtering.
The project has witnessed significant progress over the last couple of months, comparable to the progress made during the whole prior year: there has been a significant increase in development pace. It’s a well-known fact that the number of commits in a project isn’t reflective of the quality of the work, but lacking a better indicator: the project recorded 257 contributions between July 2023 and August 2024, but 229 contributions over the last two months.
Current State
Documentation
The bpfilter documentation is automatically generated and published at bpfilter.io for every merged pull request. The documentation is split in two parts: the user documentation, which explains how to use bpfilter, and the developer documentation, which details the project’s internals.
The user documentation has been updated with existing features. The “Usage” page is a good starting point if you want to try bpfilter. The developer documentation has also been improved, but to a lesser extent: it’s accurate, but not all the components are documented.
There was previously a page on bpfilter.io that would contain a reference to the complete internal API of the project. This page was filled with unorganized internal API details, brought no value to the documentation, and was very slow to generate. It has been removed in favor of a per-component documentation, which is more usable.
Apart from improving the documentation by importing more of the source code documentation into it, the developer documentation would also benefit from a high-level overview of the project: what are the different components and how they work together. A few schema and diagrams would help!
Finally, bpfilter crossed 100 stars on GitHub (125 and counting!), and a logo was designed to celebrate this milestone!
bpfilter logoFront-ends
Front-ends are the components used to translate the filtering rules coming from
nftables/iptables/bfcliinto an internal format which used to generate the BPF programs.
Let’s start with iptables: not much has changed. You can still filter on IP address (source and destination), protocol, and network interface. Not all the new matchers have yet been integrated into the iptables front-end, but will soon.
nftables, on the other hand, is not in a good shape. Recent progress on bpfilter revealed some limitations to this front-end and the need to refactor it in a way that would allow it to evolve. Unfortunately, I don’t have the bandwidth to do it right now, but it’s one of my top priorities. To provide more context, nft (nftables’ command line interface) will parse the filtering rules, convert them into nftables bytecode, and send them to the kernel. bpfilter has to work from this bytecode and convert it into an internal ruleset representation, which is not an easy task. The trick is to successfully map one or more instructions back to a single object in bpfilter (usually a matcher). I look forward to when I’ll have enough time to actually fix this once and for all.
A third front-end (and CLI) has been added to bpfilter during the last months: bfcli. bfcli provides more flexibility to combine different features provided by bpfilter: filter on XDP or a cgroup, drop a specific IPv4 address, match a layer 4 protocol or IPv6 optional field. Not all those combinations can be done using iptables or nftables. Because bfcli uses bpfilter’s internal structures to represent the filtering rules, integrating and testing new features is easier and faster: no translation layer needed. The ruleset is serialized by bfcli, sent to the daemon, and deserialized. bfcli is not meant to be the main CLI for bpfilter, nor a replacement for nftables or iptables, but a different tool for different use cases. If you are eager to know more about bfcli, read the documentation. Here’s a commented example of a ruleset:
# Create a chain attached to XDP, accept packets that doesn't match any rule.
chain BF_HOOK_XDP policy ACCEPT
rule
# Drop packets coming from 192.168.1.{131,132}
# Keep a counter of the number of packets and bytes dropped
ip4.saddr in {192.168.1.131,192.168.1.132}
counter
DROP
rule
# Drop packets coming from fc00::fbaf:7b6b:ba41:abce
ip6.saddr fc00::fbaf:7b6b:ba41:abce
DROP
Filtering rules
The way bpfilter defines filtering rules has also evolved since 2023: the structure is now simpler, easier to understand.
The chain is the high-level object used by bpfilter to represent filtering rules. A chain will be converted into a BPF program, then attached to a specific hook in the kernel. Consequently, a chain is composed of:
- The name of the hook it should filter from
- A default action (
policy) to perform in case no rule matches the packet - A list of sets, which are described below
- A list of rules

bpfilterThe set is a new type of object introduced recently, and it behaves similarly to the sets defined in nftables: you can create a set containing multiple elements of the same type, and filter on this set using a single instruction. Sets are centralized within the chain, so they could be used by multiple rules.
A rule now contains one or more matchers. A matcher represents a matching criterion for a packet: it could match against the packet’s IPv6 source address, or a TCP flag, or the layer 3 protocol type. The documentation contains the list of matchers supported by bfcli and the definition of a matcher. Apart from a list of matchers, a rule also contains a verdict to apply to the packet if the matchers match, and a boolean to state whether bpfilter should maintain a counter of bytes and packets matched by the rule.

bpfilterBytecode generation
The logic used by bpfilter to generate the bytecode evolves and grows according to the new features introduced in the codebase. Matchers are a good example of this, as they require specific bytecode to be generated to properly parse the packet and compare it to reference data.
bpfilter relies on a codegen (struct bf_cgen) object to represent the bytecode generation context. A codegen contains a reference to a chain (the ruleset), and a BPF program (struct bf_program).
Originally, bpfilter would create multiple programs for a codegen: one program for each network interface. But this was a subpar solution: some hooks are defined per-interface (e.g. XDP), while others apply to every network interface (BPF_NETFILTER). This behavior has been modified so a codegen generates a single BPF program, but multiple codegens can be defined for XDP and TC hooks. A user can choose which interface to attach their XDP or TC chain using the hook’s ifindex option.
Each BPF program generated for a codegen will be called every time a packet passes through the hook it is attached to and perform the following action:
- Initialize a small runtime context to store metadata that might be used to filter the packet more efficiently
- Execute the filtering rules in the order they are defined in the chain, such that:
- If every
matcherof the rule matches the packet, it means the rule itself matched the packet, and we can update the counter (if the rule has counters), stop processing subsequent rules, and return the rule’s verdict - If at least one of the
matchers doesn’t match the packet, we stop processing the current rule and continue with the next one
- If every
- Once we processed all the rules, if we haven’t returned yet, it means no rule matched the packet, and we can then return the chain’s policy (default action)
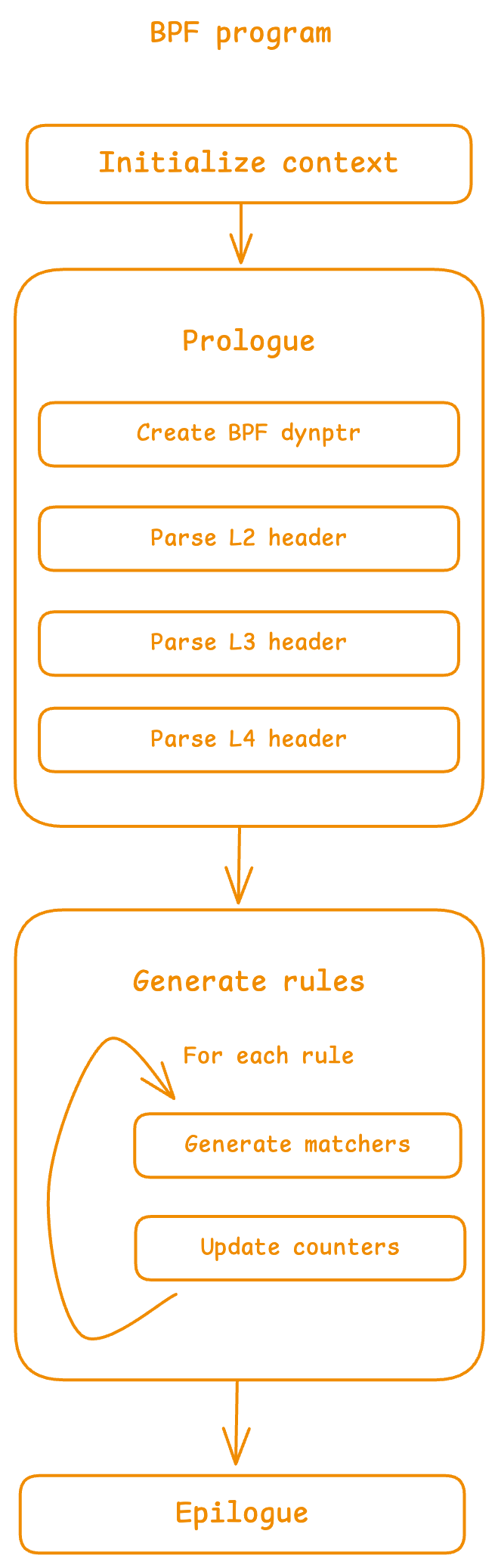
bpfilterThe main change to the bytecode generation impacts how a packet is pre-processed by the BPF program. The BPF program will parse the headers (L2, L3, L4) of the packet, store relevant metadata (protocol, header size) into the program’s runtime context. Pre-processing the packet’s headers reduces a matcher to two actions: check if the packet contains the protocol the matcher supports (e.g. only IPv6 packets can be processed by an IPv6 source address matcher), and perform the actual comparison with the matcher’s reference data. This behavior allows a chain to define rules to filter different protocols from the same layer (e.g. filtering on IPv4 and IPv6 in the same chain).
The size of the generated bytecode has been decreased by removing superfluous instructions and simplifying some features.
Tests and quality
bpfilter relies heavily on unit tests, the code coverage has increased since the last update and pull requests are not allowed to reduce the overall coverage.
Currently, there is a big blind spot to bpfilter testing, which is the bytecode generation component. The generated bytecode is not automatically tested, nor is it automatically testable at the moment. This is an issue that will grow as bpfilter supports more and more features. A solution to this issue is described in the Next section below.
Project management
Waiting to publish an update after a year is clearly too long. The intention going forward is for more regular updates, which will benefit both users and maintainers.
Until I can establish a more centralized location for the roadmap and milestones, I will add tasks to the GitHub Project and create the relevant GitHub issues for those. You can take a look at the open issues if you want to have an idea of the current work.
Next
Now let’s take some time to focus on the future of the project. Most of the latest bpfilter features are derived from an internal need at Meta, but I would like to work more on external integrations.
Extent filtering capabilities (H2 2024)
- Support for cgroup hooks, to attach a generated BPF program directly to a cgroup
- Improve
setssupport: sets are quite new tobpfilterand they will be expanded to support more types of data (IPv6, combination of IP and port, etc.) - Expand existing matchers with more operators
- Support ranges (e.g. port range)
Packaging bpfilter for RPM/DEB (H2 2024)
Currently, you need to manually build bpfilter if you want to test it. It’s cumbersome and could repel potential users. Packaging bpfilter into a DEB and RPM package will remove this limitation and could grow the number of users and contributors.
Fix nftables support (H2 2024?)
Support for nftables is essential. nftables requires a custom patch to support bpfilter, this patch is in the project’s repository, and nftables can be built easily with make nftables. I would love to see nftables use bpfilter as a way to offload filtering to XDP in the future. I would like to spend time on this task: I think it could benefit both bpfilter and nftables.
End-to-end testing (H1 2025)
End-to-end testing is currently non-existent, but it’s a critical part to ensure bpfilter is reliable. Given 3 front-ends and many matchers, end-to-end testing is the only way to quickly validate the generated programs. A solution would be to create a testing framework to perform the following:
- Manage
bpfilterlifetime: start/stop the daemon, clean-up the cache or the BPF programs if needed - Define filtering rules using
bfcli. - Craft packets and compare the program’s behavior to the expected results. The framework could send the packet to the interface the chain is attached to and read the rules counters to ensure the packet was accepted/dropped as expected.
Smarter bytecode generation
Reducing the bytecode size would improve performance of the generated BPF program. This could be done by parsing protocol headers based on usage. A chain that doesn’t contain a matcher for the TCP protocol doesn’t need to parse the TCP header, or include any logic that refers to the TCP protocol. Similarly, a chain matching exclusively on layer 3 protocols doesn’t need any logic to parse the layer 4 protocols.
Additionally, the preprocessing logic could be generated once (and cached) as it’s identical from a program to another, or even better: be implemented in C as part of bpfilter’s sources and copied directly to the final BPF programs.
Custom bytecode
What if a user could write C code to perform whatever complex packet filtering logic they want to, compile it and send it to bpfilter to be used in a chain? bpfilter could generate the BPF program as it does currently, but one of the rules (or matcher) would defer its verdict to a user-provided BPF function. This would allow users to define their own filtering logic, without relying on bpfilter’s developers to implement the required matchers.
This idea was originally suggested by Daniel Borkmann and it seems promising.
Final word
This post is long enough already, so I’ll cut it short: if you have any questions, if you need help with bpfilter, if you have any feedback, please reach out to qde@naccy.de! :)